
Delivering and improving public services under pressure
Published on
Public sector organisations are under constant pressure to keep critical services operating while simultaneously transforming the systems that support them.
Published on
Public sector organisations are under constant pressure to keep critical services operating while simultaneously transforming the systems that support them.
Published on
Like many organisations, we rely on legacy platforms and processes that are expensive to run, difficult to adapt, and slow to change. In line with the modern blueprint for Government, we are moving away from piecemeal fixes towards a more structured, cost effective approach to transformation that delivers lasting improvement.
In 2024, I took on responsibility for the Funding Service, building on six years of digital investment that had established systems to manage data, calculate and publish allocations, issue contracts, and authorise payments. Operating at significant scale and complexity, last year the service delivered 58 formula-based grants worth over £84bn across 202 funding lines, consistently reaching targets through experienced teams and well-established processes.
However, its incremental evolution has led to structural complexity, with funding delivered through a mix of systems, manual processes, and bespoke arrangements. Products had evolved beyond their original scope to manage edge cases, creating cross dependencies that made the service harder to scale or adapt. Change was often slow and costly, and siloed teams limited our ability to view and improve the service end to end.
These are not failures of individual systems or teams. They are symptoms of a service that has become fragmented, and where variance is absorbed rather than removed.
Over the first year, the focus was on creating the space to address this. We reshaped teams to move towards a more service-led, outcome-focused model, supported by better insight into user and service needs (Breaking down silos). In parallel, we redesigned our contract model, separating run and refine from improve and grow (Rethinking our contracts), reducing supplier reliance, improving accountability, and giving us greater control.
These changes reduced running costs and created a clearer separation between work on existing systems and improvement work, allowing us to reinvest savings in discoveries to shape how the service evolves. With those foundations in place, the next phase is underway, delivering our transformation projects, creating our service north star, and developing a path to a stable, cost effective run state.
Discovery work in year one highlighted consistent problems in how funding is communicated:
Our aim for Alpha was to prove that we could move from manual, bespoke processes to a scalable, data driven service that delivers clear and accurate information quickly.
The team designed a series of reusable patterns for funding values, payment schedules, remittance information, and guidance, and tested them with internal users and education providers. In parallel, they assessed the data used in the service to see if it could support the automation of statements.
Through proof of concept work and a small private beta, they built a microservice that generates statements automatically. Live data is now pulled via APIs rather than being shared as static extracts creating a platform that can support future growth.
The first data driven statements went live in April this year, with rollout across all funding streams planned. This will reduce the time to produce statements from weeks to hours, by removing the need to collect data from multiple spreadsheets and then build bespoke HTML versions. End users will receive consistent information in a single place.
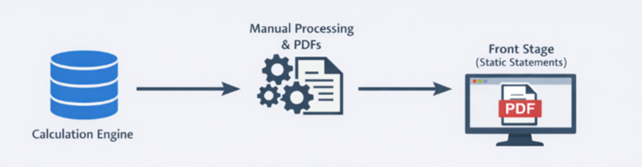
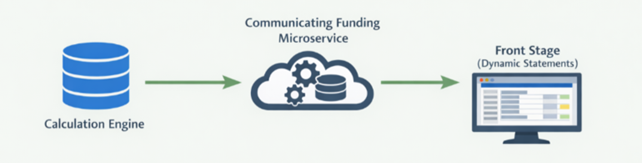
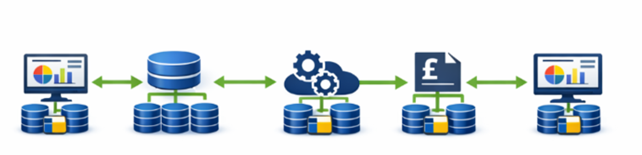
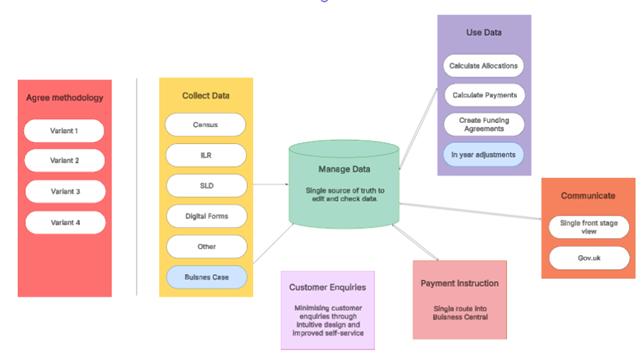
Another key finding from our Discovery work was how disjointed the use of data across the service was. Right now, operational data is spread across multiple systems, teams, and formats, both online and offline, requiring it to be copied, reworked, and moved between tools. These handovers can introduce errors, inconsistencies, and duplication, driving the need for additional QA and assurance work. Accessing information relies on manual extracts that are time-consuming and quickly become outdated.
We also discovered that many grants remain mostly offline due to the effort required to get them set up on our current systems. In general the digital systems are used for the biggest grants meaning smaller and shorter term funding streams are disproportionately expensive to deliver using bespoke offline processes.
The operational data layer aims to address this at the root. Instead of each team holding its own version of the truth, it creates a single, trusted place where funding data is validated, updated and owned. The idea is that operational changes, in-year adjustments and provider updates can be made once, with clear approval and audit trails, and then flow automatically to every part of the service that needs it.
This shifts the model from a linear process to more of a hub and spoke approach, reducing duplication and unnecessary dependencies.
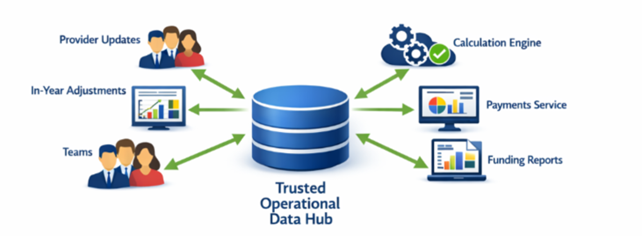
This reduces reliance on individual knowledge and workarounds, and improves auditability and traceability. It also makes the platform easier to extend and adapt, whether onboarding new funding or responding to policy changes in existing funding lines. It will also reduce costs by removing duplicate cuts of data currently stored in multiple systems.
This is a shift from our previous approach. Rather than trying to manage increasing complexity, we are aiming to remove it.
Running a complex live service makes prioritisation difficult. Urgent issues are constant, but quick fixes often create isolated solutions that increase variation and make the service harder to operate.
Thinking about communications and data as organisation-wide problems was made possible by introducing outcome-focused teams that could work across system boundaries. This started to move us away from reactive fixes and towards more joined up, end to end solutions.
These outcome-focused teams also change how we approach delivery. Rather than treating data collection, calculations and payments as separate capabilities, we can deliver complete journeys for a smaller number of grants and learn from them iteratively. This allows us to test approaches against a broader cross-section of funding models earlier, helping us design for complexity from the start rather than hitting barriers later down the line.
To build on this and make it consistent, we created a North Star for the Funding Service. It builds on the changes from year one and gives us a clear way to assess value, make trade offs, and focus on service wide outcomes.
The north star builds on four core pillars of the service strategy:
The North Star describes the future operating model, focusing on capabilities rather than systems. It describes a service where:
These principles define what “good” looks like across the service. They help us decide not just what is urgent, but what is worth doing in the longer term.
To support this, we also introduced clearer governance structures and prioritisation. A transformation board now brings together policy implementation, operational delivery and digital delivery to collectively decide:
We also introduced a simple tagging model to delivery planning to better understand where effort is spent in each space:
These categories are used to:
Through this work, it became clear that many smaller system changes were not delivering enough value to justify their cost, particularly when set against the potential of the transformation work.
We also saw that by shifting focus towards transformation, we could reduce activity that introduces additional complexity, and start addressing the underlying causes instead.
From this, we made a deliberate decision to explore what a defined run state could look like, focusing on how to run the service more efficiently while continuing to invest in its future.
A run state is a multidisciplinary team responsible for maintaining services that are no longer in active development.
To work out how to get there we looked to answer the following four questions:
Earlier work had grouped systems into domains, but teams still worked largely in isolation.
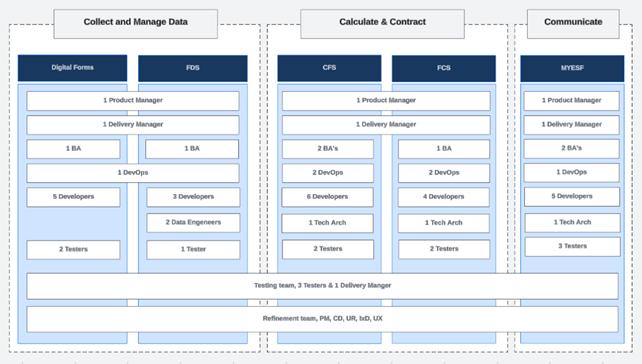
We found three core reasons for this:
Work is more manual and fragmented than it needs to be. We saw repeated manual testing and data handling, along with a heavy reliance on spreadsheets and single points of knowledge.
There is significant variation in how funding is delivered. Some of this is necessary due to policy or legal constraints, but much comes from legacy decisions and accumulated workarounds. These inconsistencies are a major source of inefficiency.
Differences in technology stacks, environments and deployment approaches limit opportunities for efficiency and make it harder for teams to work consistently.
Together, these factors prevent us from working consistently and sharing capability and processes across systems. By tackling these areas, we expect to introduce significant efficiencies over the next 12 to 18 months.
A key part of this is creating a consistent technical foundation. The Funding Service has grown organically across multiple tenancies, architectures and tooling approaches. While this supported early delivery and pace, it left us with reduced flexibility, and increased the cost of running the service.
In practice, environments, deployments, monitoring and security often depend on bespoke knowledge and coordination across teams. This creates risk and slows delivery, particularly during peak periods.
To address this, we are building a central developer platform that provides standard hosting patterns, deployment pipelines, monitoring and security processes. All systems will use these shared components, removing the need for bespoke infrastructure and reducing duplication. This will increase automation, improve reliability, and reduce the operational overhead of maintaining environments.
Looking further ahead, we have a more ambitious target focused on reducing unnecessary variation in policy design. From our work with policy implementation, we’ve identified areas where consistency already exists:
This gives us a foundation to start defining reusable service patterns and to better inform policy decisions. The aim is not to remove variation entirely, but to make it visible, consistent and easier to manage.
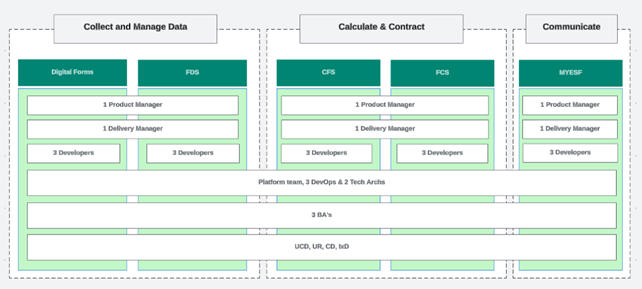
At this stage, we would move from a product-based model to a capability-based one. The focus shifts to a small set of core Funding Service capabilities: data collection, calculation, contracting, payment and communication. A smaller team then maintains these shared capabilities and the platform that supports them.
Combined with the platform and architectural changes, this enables a capability-based run state. Services become more composable, easier to evolve, and cheaper to operate at scale.
The move to a run state brings a number of benefits:
Getting buy-in for foundational changes has been one of the biggest challenges. Work like the data layer is critical, but harder to make visible. This contrasts with the communications work, where progress is easier to see and test, making it simpler to build momentum.
The insight team also took time to settle. Its role is to look across the whole service and help identify where we need to focus. There is a risk for a team like this to drift into a more traditional UCD support role, which was never the intent. After an initial bedding in period, the team is now starting to shape priorities more directly, using evidence to guide what we do, not just how we do it.
Another challenge has been defining the true cost of running the service. Without a clear baseline, it is difficult to assess the impact of transformation work. Establishing that baseline has taken longer than expected due to how intertwined the work is.
It's also challenging to find the right balance between running and improving a service alongside bigger transformational work. Legacy systems make small changes deceptively expensive. Work that initially appears incremental can quickly require significant rebuilding.
Finally, communication across a large team is always difficult to get right. There is a balance between being transparent and avoiding unnecessary uncertainty while plans are still evolving.
Year 1 was about understanding the service and creating the conditions for change. Year 2 has focused on turning that insight into action through targeted transformation projects, while continuing to deliver and iterate the live service.
Year 3 will focus on embedding these foundational changes, expanding the service to support a wider range of funding models, and becoming more intentional about the improvement activity we take forward as we move towards a leaner run state.
For Communicating funding we want to roll out automated statements to all funding lines and identify opportunities to reuse this model, particularly in the contracting space. We also want to make sure ongoing development of our front stage system aligns with the new communications microservice and support the decommissioning of high-cost legacy systems in that space.
For the Data layer we want to build a working prototype to test assumptions and validate early design decisions and then use this to learn before scaling the platform and enabling future automation of payment instructions and calculations.
With the variation work we want to bring policy, and delivery work closer together to jointly develop and validate a small set of service patterns that reduce unnecessary variation and guide future policy designs. These patterns can then be used to underpin a clear policy design menu, so policy teams have real delivery choices that work in practice.
Most of all, we need to move away from polishing what exists and making short term fixes that further fragment the service. We want to run the live service as efficiently as possible, while making sure all new work improves the service as a whole. To achieve that we need to start solving problems and stop managing the complexity.





